Memora
Memora (Re-Moment)
言語選択: English | 한국어 | 日本語 | 简体中文 | Español | Français | Português | हिन्दी | বাংলা | العربية

![]()
![]()
![]()
![]()
![]()
Memora(サブタイトル:Re-Moment)は、ユーザーの写真ライブラリをローカル優先で分析し、関連する瞬間を短いメモリーストーリー動画にまとめる iPhone/iPad アプリです。プライベートな写真インデックス作成、確認可能なおすすめ、編集可能なストーリー下書き、デバイス上でのレンダリングを中心に設計されています。Pro Vision AI は、より高品質なキャプションとリモート補助インデックス作成のための任意の有料機能です。
📑 目次
📱 アプリのスクリーンショット (App Screenshots)
| スクリーンショット | スクリーンショット | スクリーンショット | スクリーンショット | スクリーンショット |
|---|---|---|---|---|
 |
 |
 |
 |
 |
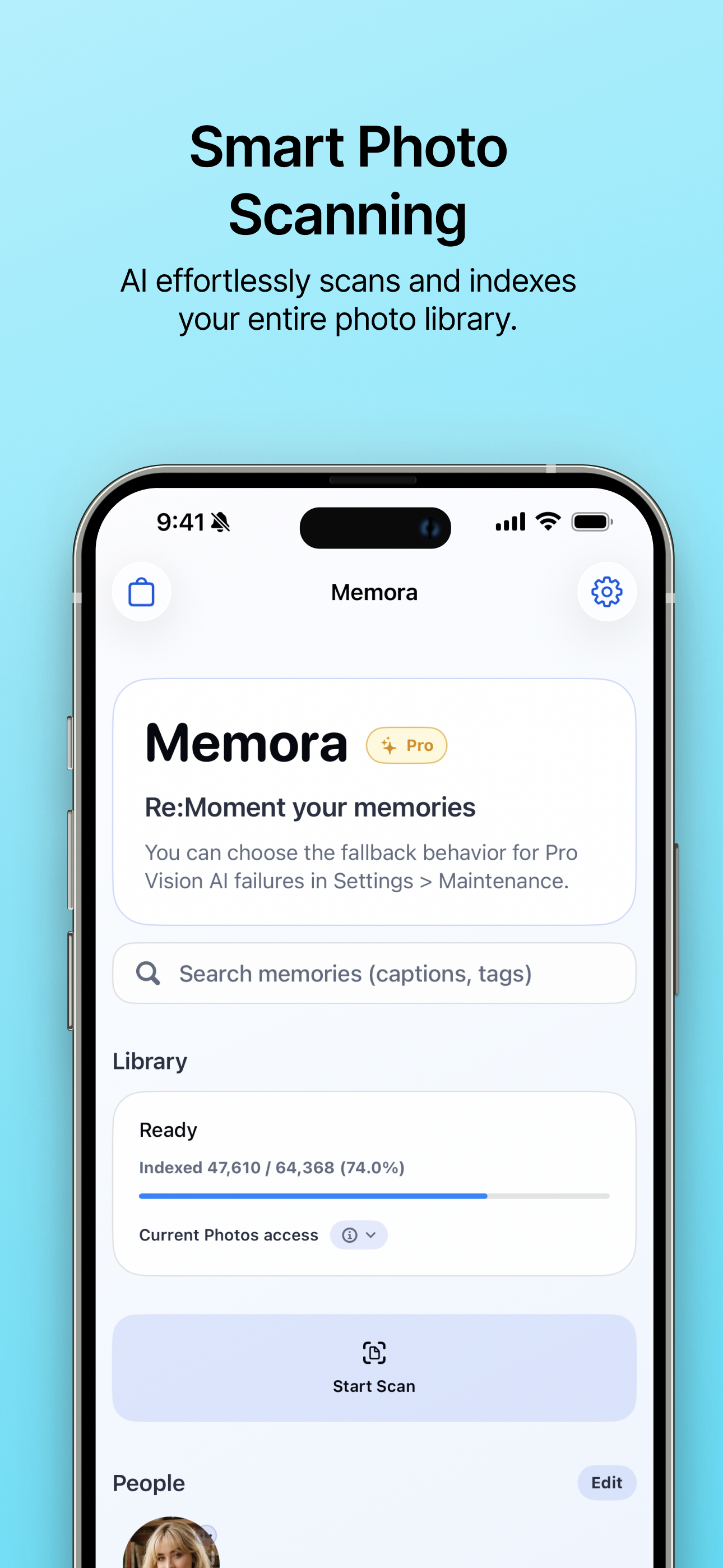
| スマートな写真スキャン AI が写真ライブラリ全体を自動的にスキャンし、インデックスを作成します。 |
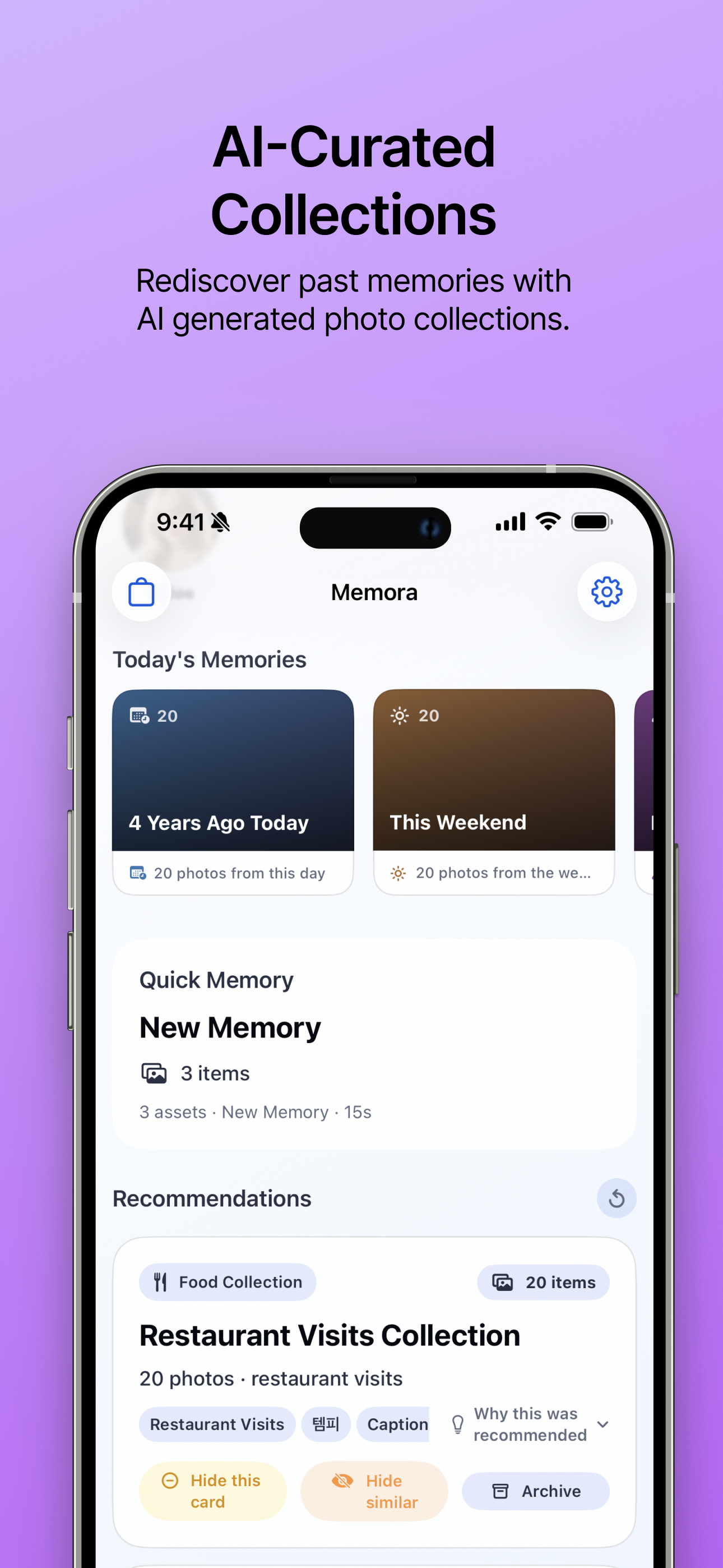
AI おすすめコレクション 自動生成される写真コレクションで、過去の思い出を再発見しましょう。 |
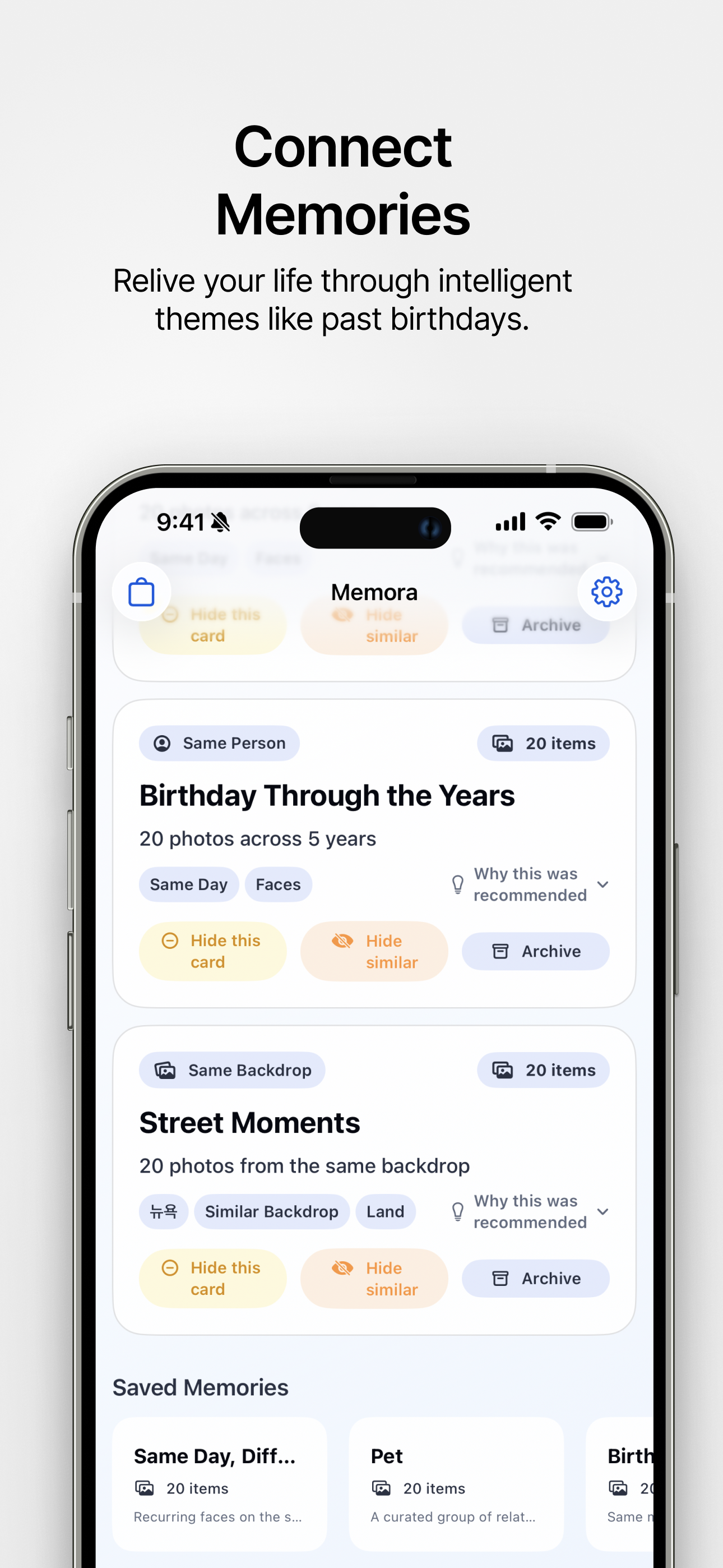
時を超える思い出 過去の誕生日など、インテリジェントなテーマを通して人生を振り返ります。 |
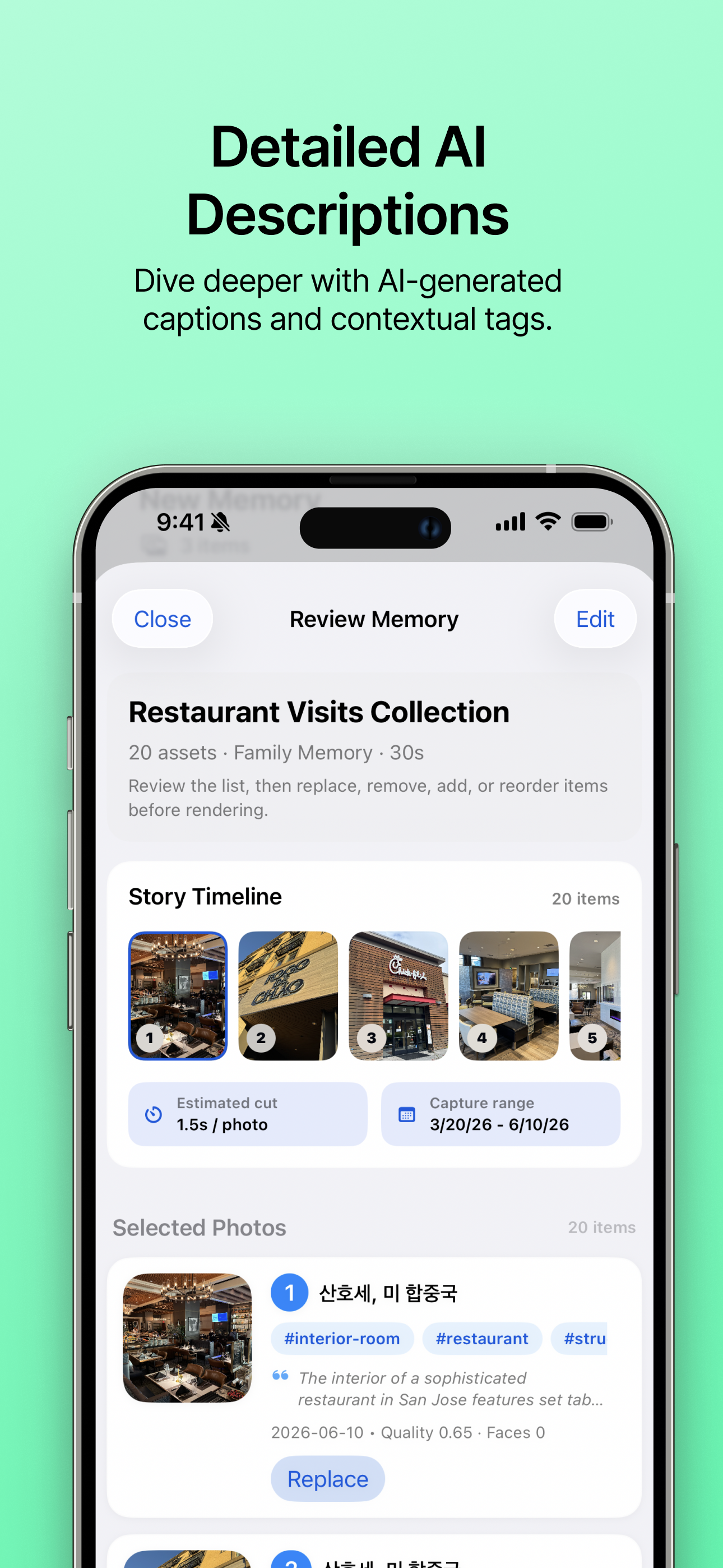
AI でさらに深く AI 生成のキャプションやコンテキストタグで詳細まで分析します。 |
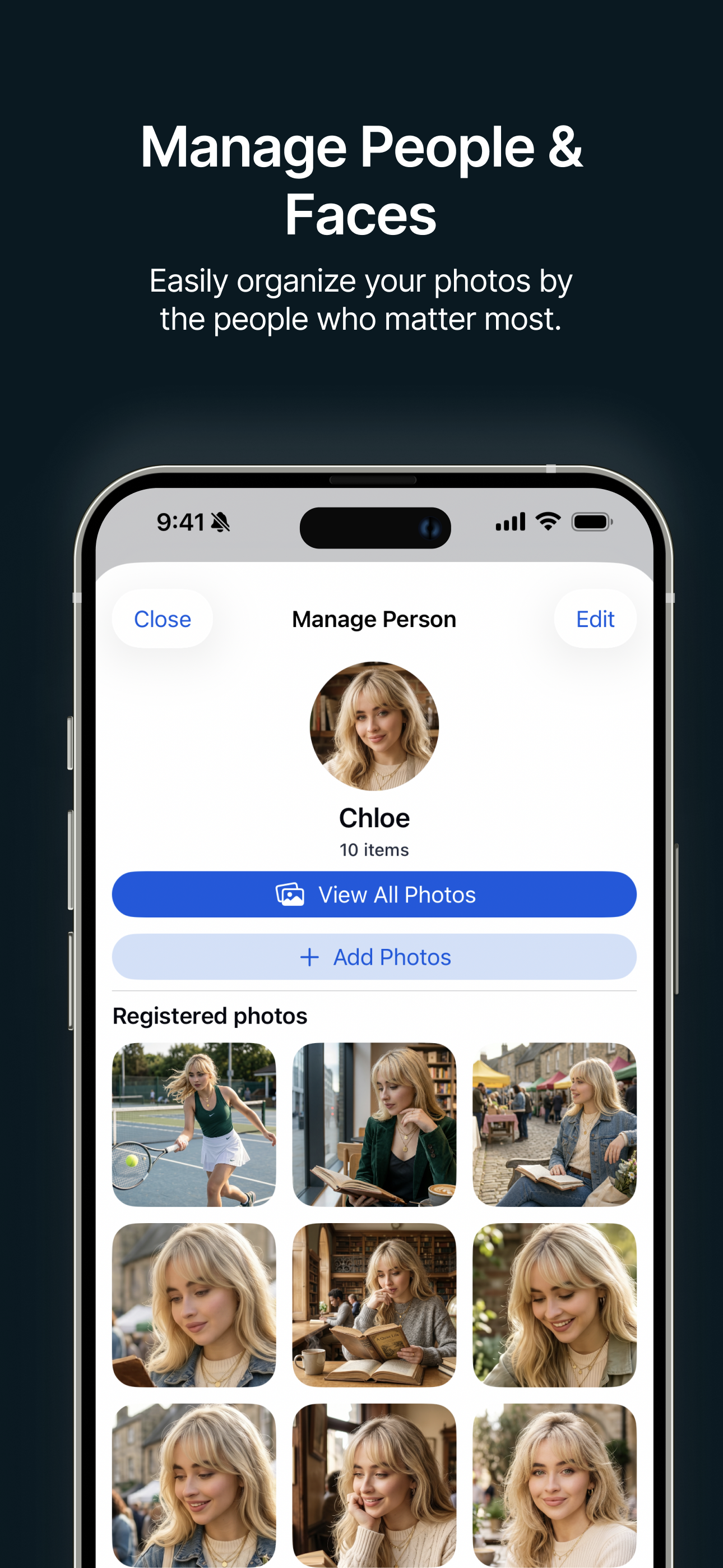
人物ごとに整理 大切な人ごとの写真を簡単に整理して集めることができます。 |
 |
 |
 |
 |
 |
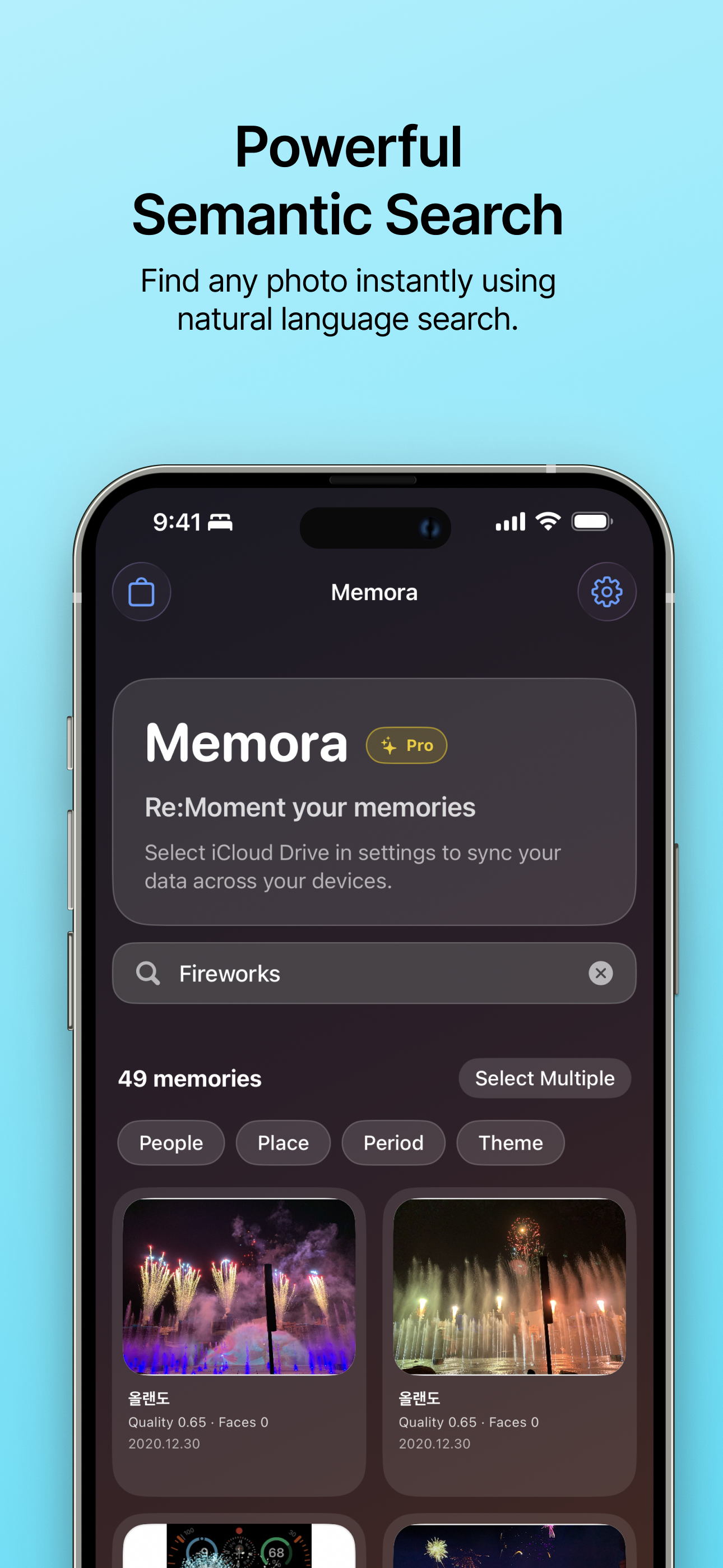
| 瞬時の写真検索 自然言語検索を使って、探したい写真を魔法のようにすぐ見つけます。 |
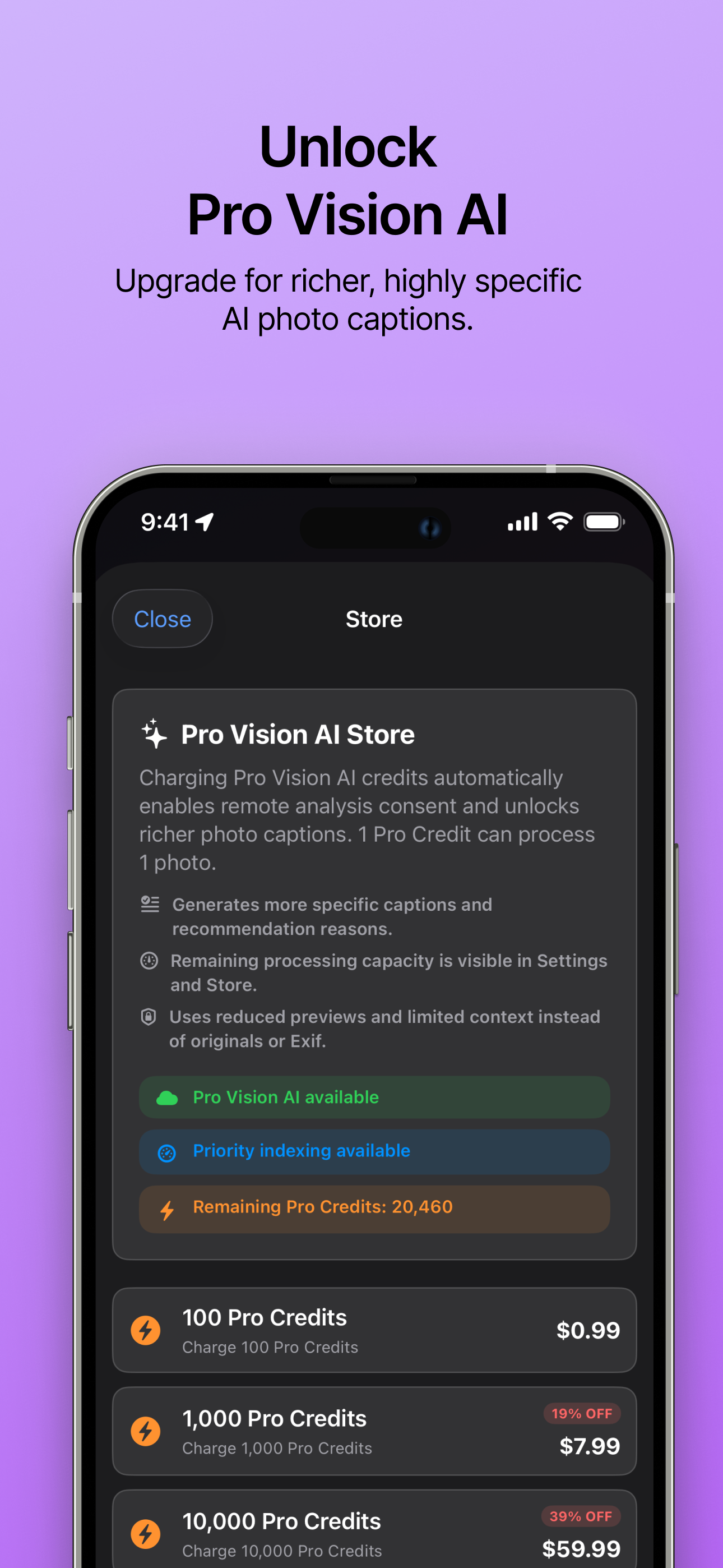
Pro Vision AI アップグレードして、より豊かで具体的な AI 写真キャプションを利用できます。 |
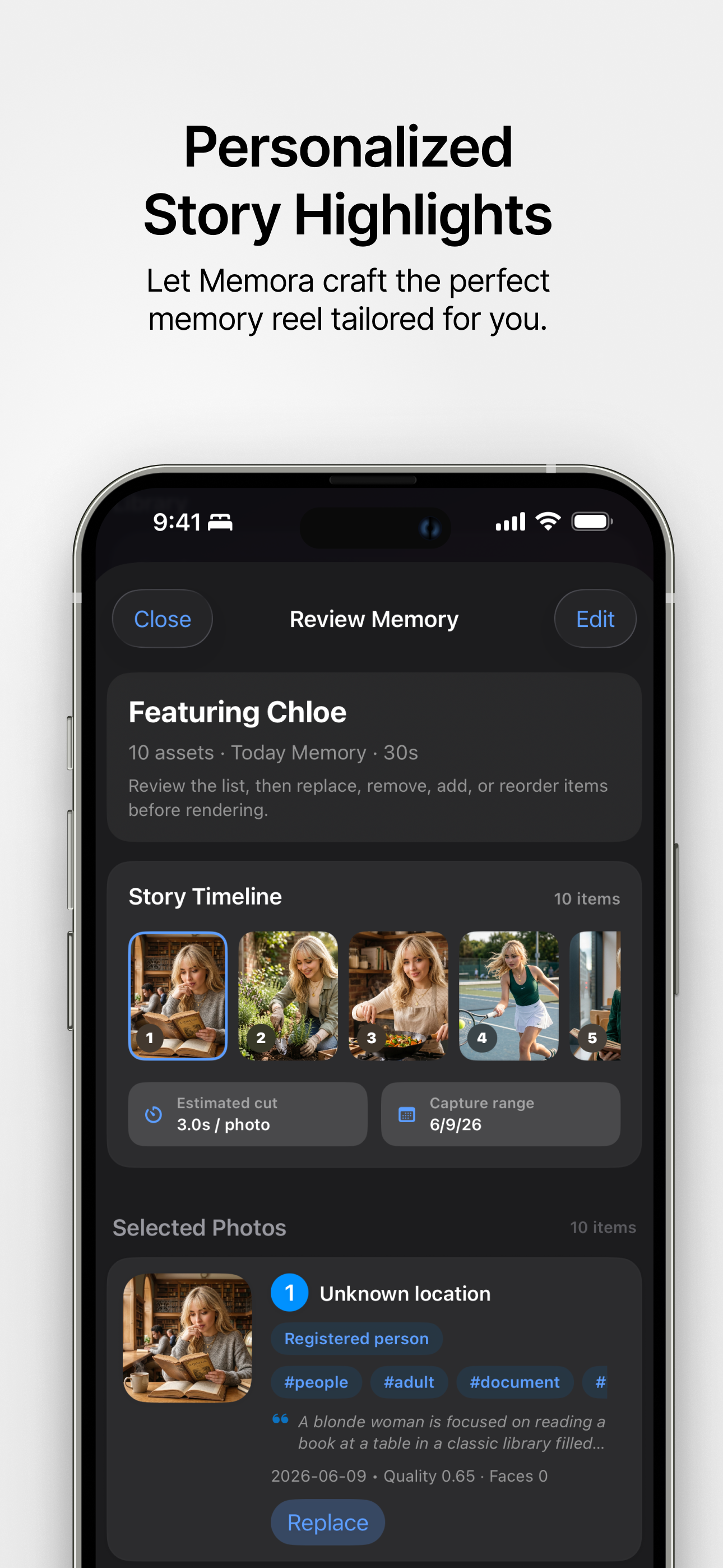
パーソナライズされたハイライト あなただけのためにカスタマイズされた完璧なメモリーリールを作成します。 |
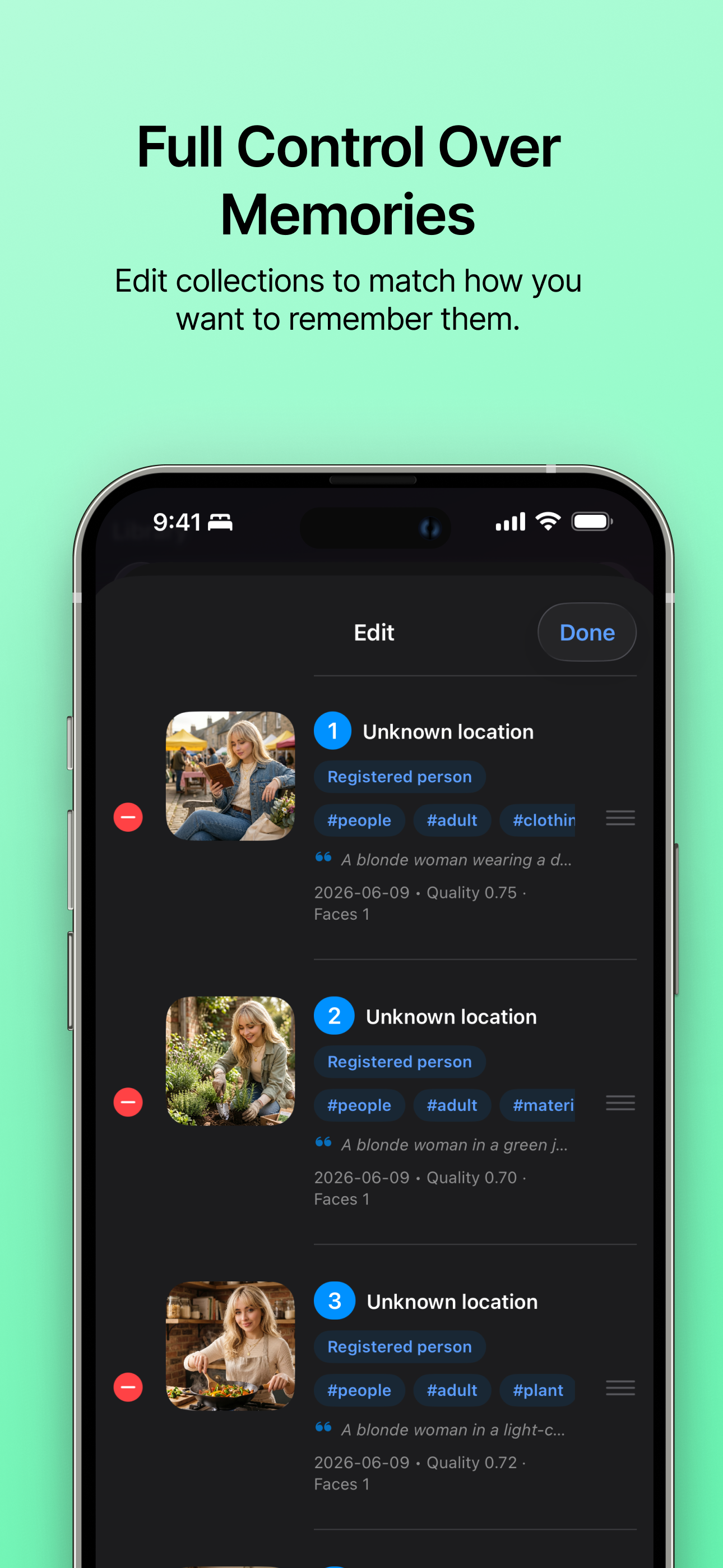
カスタムギャラリー編集 コレクションを簡単に編集し、残したい思い出の形に合わせることができます。 |
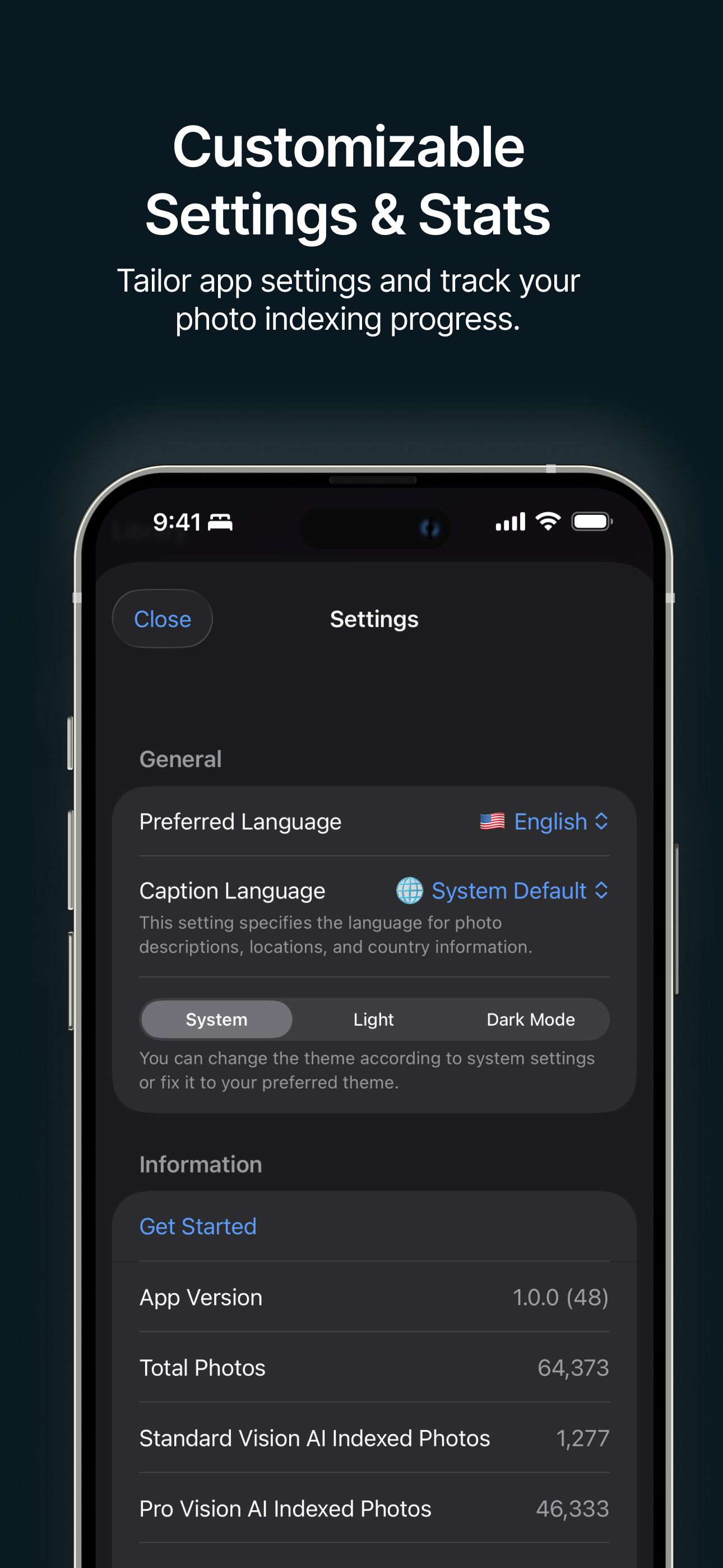
設定と統計 アプリの設定を調整し、写真のインデックス作成の進捗を追跡します。 |
✨ 主な機能
スマートストーリー推薦
- 写真ライブラリのインデックス作成: PhotoKit で許可された写真を読み取り、日付、位置、 favorites、メディア種別、品質、顔の数、シーン、キャプション信号を抽出します。
- 推薦カード: 同じ人物、似た背景、食べ物、季節、都市/旅行、時間スナップショット、意味のある瞬間、動画ハイライトなどからストーリー候補を作成します。
- 検索とメンテナンス: インデックス済み写真をローカル検索でき、翻訳補完、整合性修復、推薦フィードバックのリセット、インデックス再開補助を提供します。
- スキャン優先度設定: アプリの設定からインデックス作成のスキャン優先度を直接調整できます。
- クイックスキャン(Quick Scan)モード: より速く結果を得るためのルールベースのスキャンオプションを提供します。
確認可能なメモリーストーリー
- ストーリーレビュー: レンダリング前に推薦ストーリーを確認し、フルスクリーンプレビューと検索を使って写真の置換、削除、追加、並べ替えを行い、顔が明瞭な写真から代表人物を登録できます。
- フィードバック制御: 生成済みストーリーのアーカイブ、特定推薦の非表示、類似推薦タイプの除外、直近フィードバックの取り消しができます。
- 人物サポート: 登録済み人物プロフィールは、人物中心のストーリー作成と今後の推薦品質改善に使われます。
ローカル優先の Vision と保存
- デフォルトはオンデバイス: 標準インデックスとフォールバックキャプションは、ローカルの PhotoKit、Vision、メタデータ分析で処理されます。ユーザーが Pro Vision AI を有効にして使用しない限り、写真はサーバーへ送信されません。
- ローカルデータベース: インデックス、ストーリー、レンダー作業、設定、チェックポイント、人物プロフィールは SwiftData でアプリサンドボックス内部のみに安全に保存されます。
- 診断: MetricKit 診断はクラッシュ、ハング、起動、CPU、ディスク書き込み問題の調査に使われます。診断にはユーザーの写真ファイルは含まれません。
- AIダウンロードUIの改善: オンデバイスVision AIモデルのダウンロードの進捗状況と動的アップデートのフィードバックが向上しました。
- 動的なVision AIモデルマニフェスト: オンデバイスMLXモデル構成のバックエンド駆動型アップデートをサポートします。
Pro Vision AI
- 任意の有料機能: Pro Vision AI はサーバー側プロキシを使い、拡張 VLM キャプションとリモートインデックス処理量の管理を行います。処理量がない場合やサーバーに接続できない場合でも、アプリは標準のローカル Vision AI で利用できます。
- サーバー側制御: バックエンドは StoreKit 権限状態の検証、短期アクセストークンの発行、処理量管理、プロバイダー API キーの保護、冪等性、悪用防止信号の追跡を行います。
- 画像処理: 画像ペイロードは要求されたキャプション処理のためだけに転送されます。サービスは元画像バイトを製品利用や AI 学習目的で保存しないよう設計されています。ただし、権限、処理量、デバッグ、セキュリティ、悪用防止のため、サニタイズ済みリクエストメタデータ、プロバイダー応答テキスト、リクエスト状態、処理量カウンター、デバイスハッシュ、エラー情報などの運用記録を保持する場合があります。
動画レンダリングと保存
- ネイティブレンダラー: メモリーストーリーは、キャッシュされた写真アセットをもとに AVFoundation で標準 30fps を目標としてレンダリングされ、dissolve、slide、wipe、zoom 系の動きとトランジションを使用します。
- Photos への書き出し: レンダリング前に iCloud 専用アセットのローカルコピーを準備し、完成動画は Photos add-only 権限と Photos 互換 MOV fallback 経路で保存します。
- 進行状況とキャンセル: ダウンロード、レンダリング、保存、失敗、キャンセル、復旧状態をアプリで表示します。
❓ FAQ(よくある質問)
-
インデックス作成が遅すぎるのはなぜですか? Memoraには標準モードとProモードがあります。標準モードはデバイス上のAIモデルを直接使用するため、オンデバイス処理の性質上、時間がかかる場合があります。より高速なインデックス作成と高品質なキャプションを利用するには、ストアでPro Vision AIサブスクリプションをご購入ください。
-
写真はサーバーに保存されますか? いいえ、写真は当社のサーバーに保存されることはありません。標準モードでは、すべての処理がデバイス上でローカルに行われます。Pro Vision AIを使用する場合でも、画像は処理のために一時的にサーバーに送信されるだけで、直ちに破棄され、保存されたりAIの学習に使用されたりすることはありません。
-
アプリを使用するには何か購入する必要がありますか? いいえ、Memoraの主要機能は完全に無料です。標準モードを使用して、無料で写真をインデックス化し、ストーリーを作成できます。Pro Vision AIは、より高速な処理と豊かな画像キャプションを求めるユーザー向けのオプションの有料機能です。
-
Proを使用していますが、インデックス作成がまだ遅いです? バックグラウンド通信の問題の可能性があります。アプリを強制終了し(アプリスイッチャーで上にスワイプ)、再度開いてみてください。また、Proモードはサーバーとの通信が必要なため、安定したインターネット接続があることを確認してください。
-
データをバックアップできますか? はい。Memoraの「設定 > バックアップと復元 > データベースのバックアップ」機能を使用すると、インデックス、ストーリー、設定などのデータをファイルに書き出して任意の場所に保存できます。(注:これはアプリのデータのみをバックアップし、元の写真ファイルはバックアップしません。)
-
バックアップしたデータを復元できますか? はい。Memoraの「設定 > バックアップと復元 > データベースの復元」機能を使用すると、書き出したバックアップファイルからデータを復元できます。
-
写真のインデックス作成中に画面が暗くなるのはなぜですか? インデックス作成は画面がオンになっている間のみ進行します。バッテリーを節約し、画面の焼き付きを防ぐため、Memoraは5分間継続してインデックスを作成した後、自動的に画面の明るさを最小に下げます。長時間のインデックス作成中は、デバイスを電源に接続することを強くお勧めします。
-
夜間に画面が明るすぎます? デバイスの明るさを手動で下げるか、ダークモードを使用してください。インデックス作成をオンにしたままにすると、5分後にMemoraが自動的に画面を暗くします。
-
日中に画面が暗すぎます? デバイスの明るさを手動で上げるか、ダークモードを無効にしてください。Memoraはバッテリーを節約するため、インデックス作成の5分後に意図的に画面を暗くします。画面を確認する必要がある場合は、画面をタップするか、コントロールセンターから手動で明るさを調整してください。
-
インデックス作成中にデバイスが熱くなります? 標準モードはデバイスのプロセッサとNeural Engineを大きく使用するため、自然に熱くなります。Proモードは重い計算をサーバーにオフロードし、デバイスの熱とバッテリー消費を大幅に削減します。熱が不快な場合は、インデックス作成を一時停止するか、充電器に接続するか、より低温で高速な体験のためにPro Vision AIにアップグレードすることをご検討ください。
📌 重要な注意事項
- Memora はストーリー推薦のために写真読み取り権限を必要とします。限定アクセスにも対応しますが、意図した体験にはフルアクセスが適しています。
- レンダリング済み動画を写真アプリに保存するには、写真追加権限が必要です。
- Pro Vision AI は、選択された画像のキャプションデータを生成するために、バックエンドと設定された VLM プロバイダーに一時的に送信します。ただし、すべての写真はキャプションが生成された後、保存されることなく直ちに削除されますので、安心してご利用ください。
- AI 生成のキャプションや推薦は不正確な場合があります。レンダリングまたは共有する前に内容を確認してください。
- 商品名、処理量、価格、対応プラットフォームは App Store リリース前後で変更される場合があります。
🛠 技術スタック
クライアント
- Swift 6, SwiftUI, SwiftData
- PhotoKit, Vision, AVFoundation, MetricKit
- MLX Swift LM / MLX VLM 関連パッケージ, Swift HuggingFace, Swift Transformers
サーバー
- FastAPI, Uvicorn, Starlette
- PostgreSQL, SQLAlchemy, Alembic, Psycopg 3
- Pydantic, Pydantic Settings, HTTPX
- StoreKit とトークン検証経路のための PyJWT, cryptography
📜 ポリシーとライセンス
📄 ライセンス
Copyright © 2026 MFLab-AI (https://lab.missflash.com/). All rights reserved.
別途書面によるライセンスがない限り、Memora のソースコード、アセット、ブランド、文書、および関連資料は proprietary として保護されます。サードパーティのオープンソース構成要素は、それぞれのライセンスに従います。