Memora
Memora (Re-Moment)
Seleccionar idioma: English | 한국어 | 日本語 | 简体中文 | Español | Français | Português | हिन्दी | বাংলা | العربية

![]()
![]()
![]()
![]()
![]()
Memora, con el subtítulo Re-Moment, es una app para iPhone y iPad con enfoque local-first que analiza la biblioteca de Fotos del usuario y convierte momentos relacionados en videos cortos de recuerdos. La app se centra en indexación privada de fotos, recomendaciones revisables, borradores de historias editables y renderizado en el dispositivo. Pro Vision AI es una opción de pago para subtítulos de mayor calidad e indexación asistida remotamente.
📑 Tabla de contenidos
- 📱 Capturas de pantalla de la app (App Screenshots)
- ✨ Funciones principales
- ❓ FAQ (Preguntas Frecuentes)
- 📌 Notas importantes
- 🛠 Stack tecnológico
- 📜 Políticas y licencias
- 📄 Licencia
📱 Capturas de pantalla de la app (App Screenshots)
| Captura de pantalla | Captura de pantalla | Captura de pantalla | Captura de pantalla | Captura de pantalla |
|---|---|---|---|---|
 |
 |
 |
 |
 |
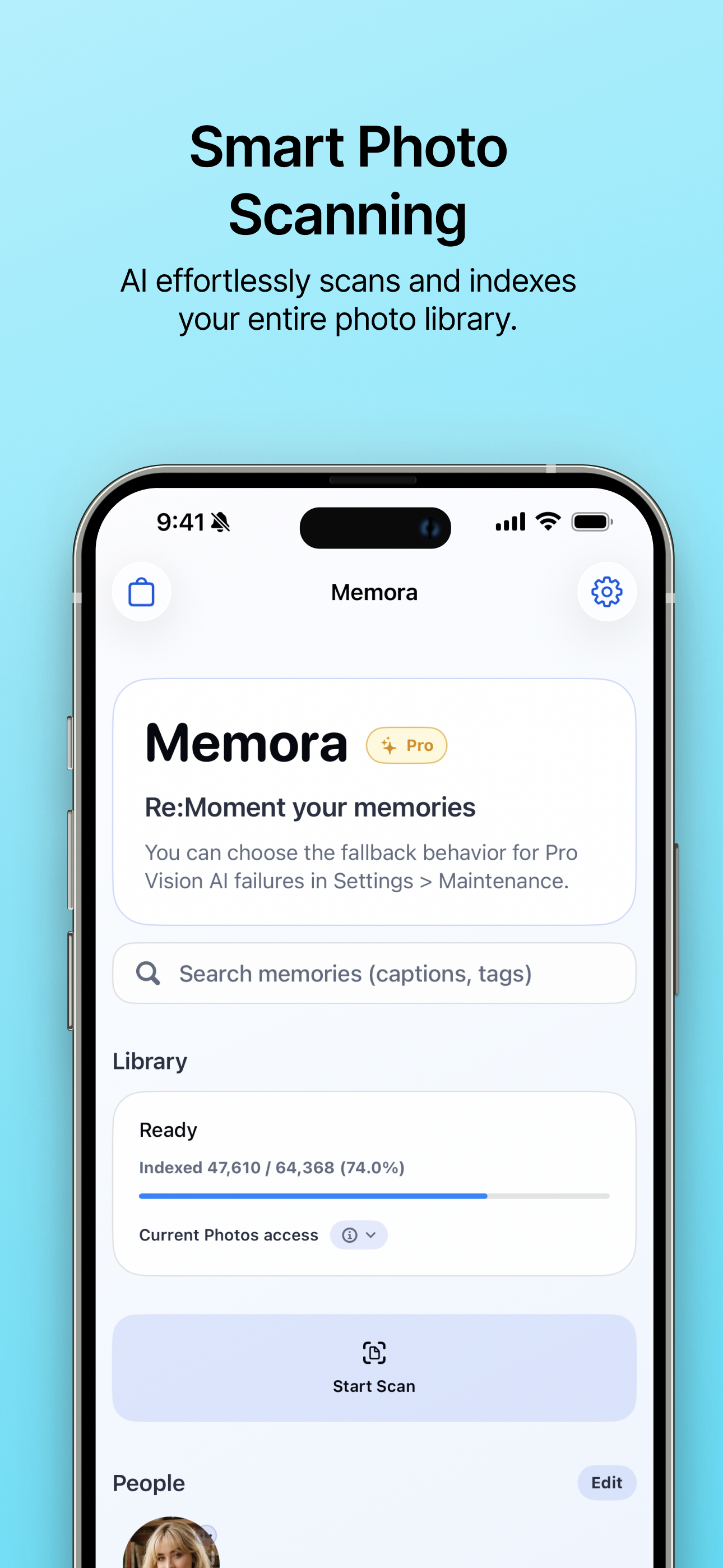
| Escaneo inteligente de fotos La IA escanea e indexa sin esfuerzo toda tu biblioteca de fotos. |
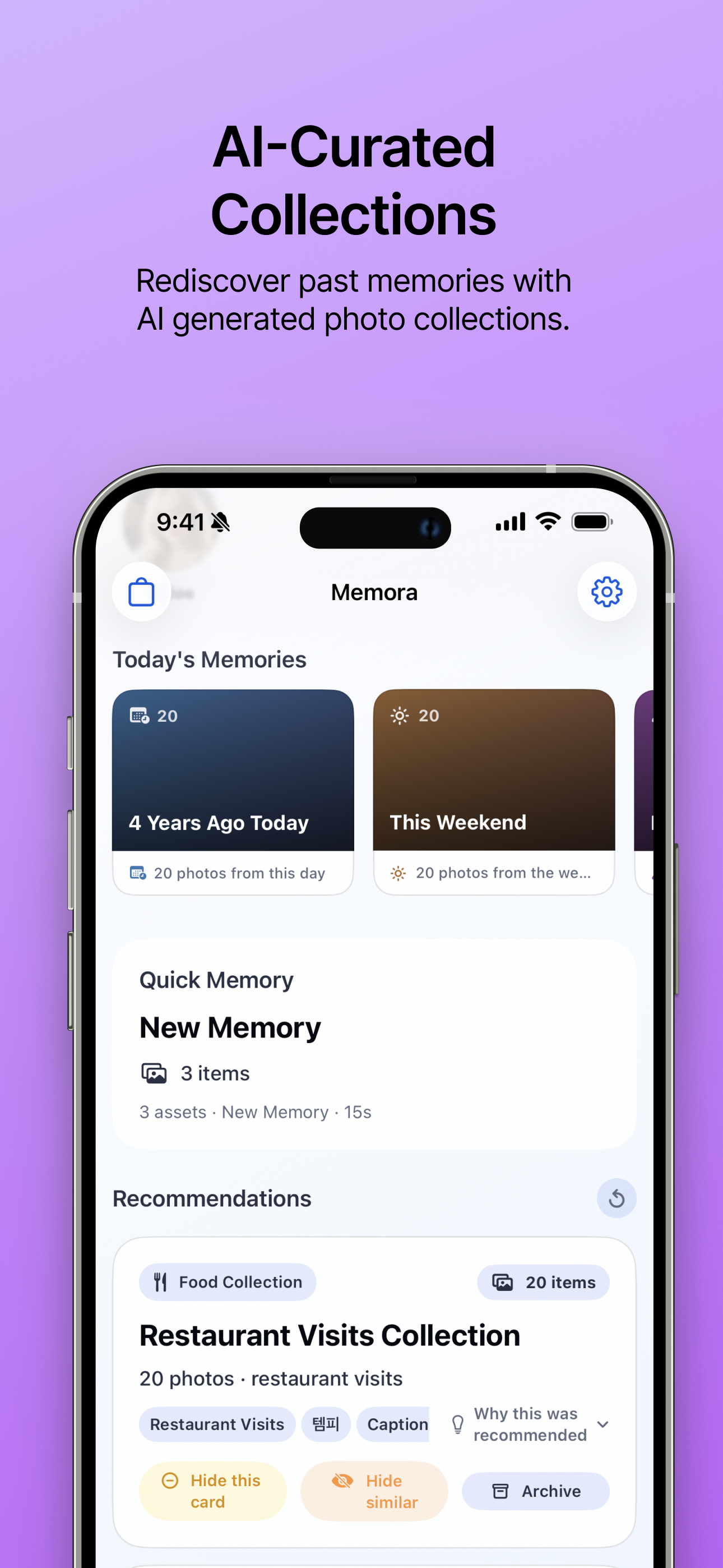
Colecciones seleccionadas por IA Redescubre recuerdos del pasado con colecciones generadas automáticamente. |
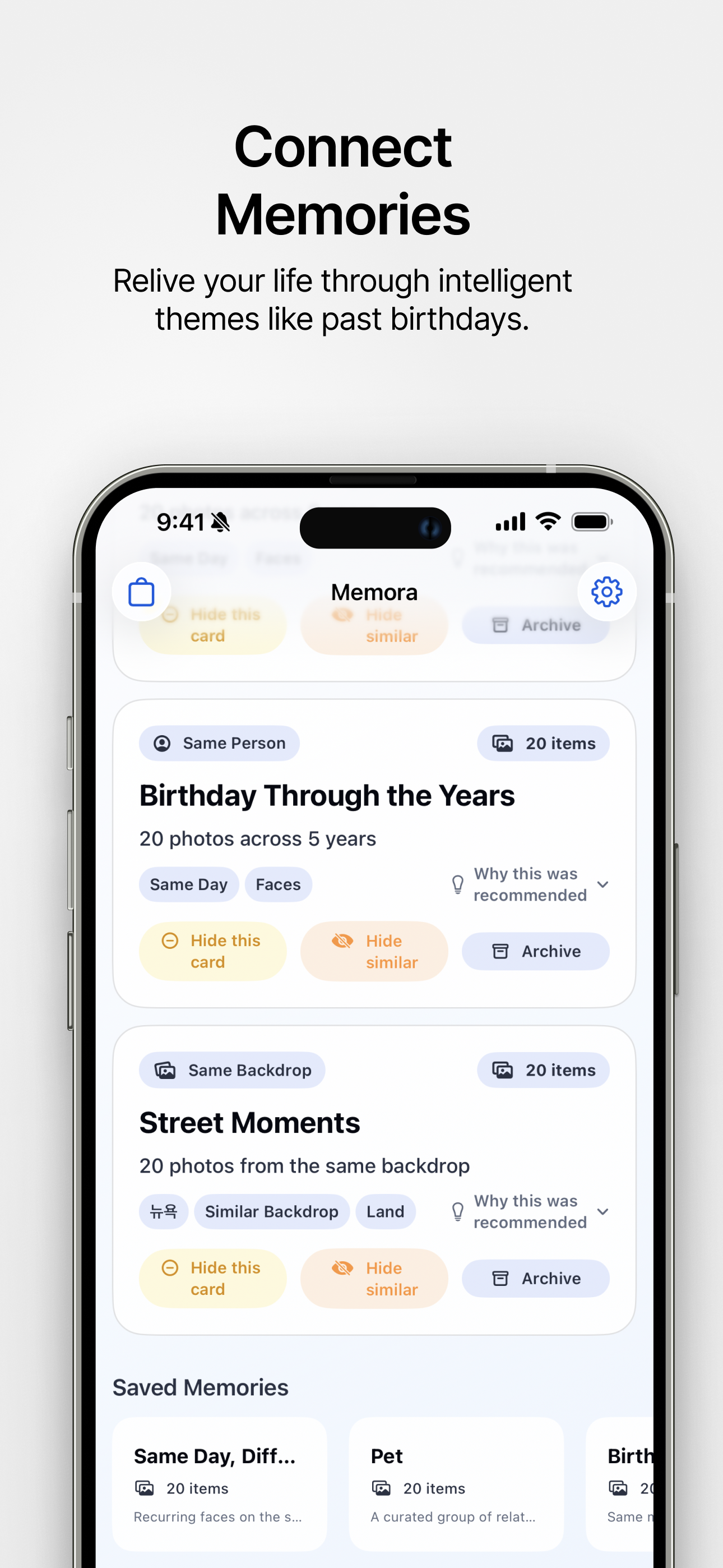
Conecta recuerdos en el tiempo Revive tu vida con temas inteligentes como cumpleaños pasados. |
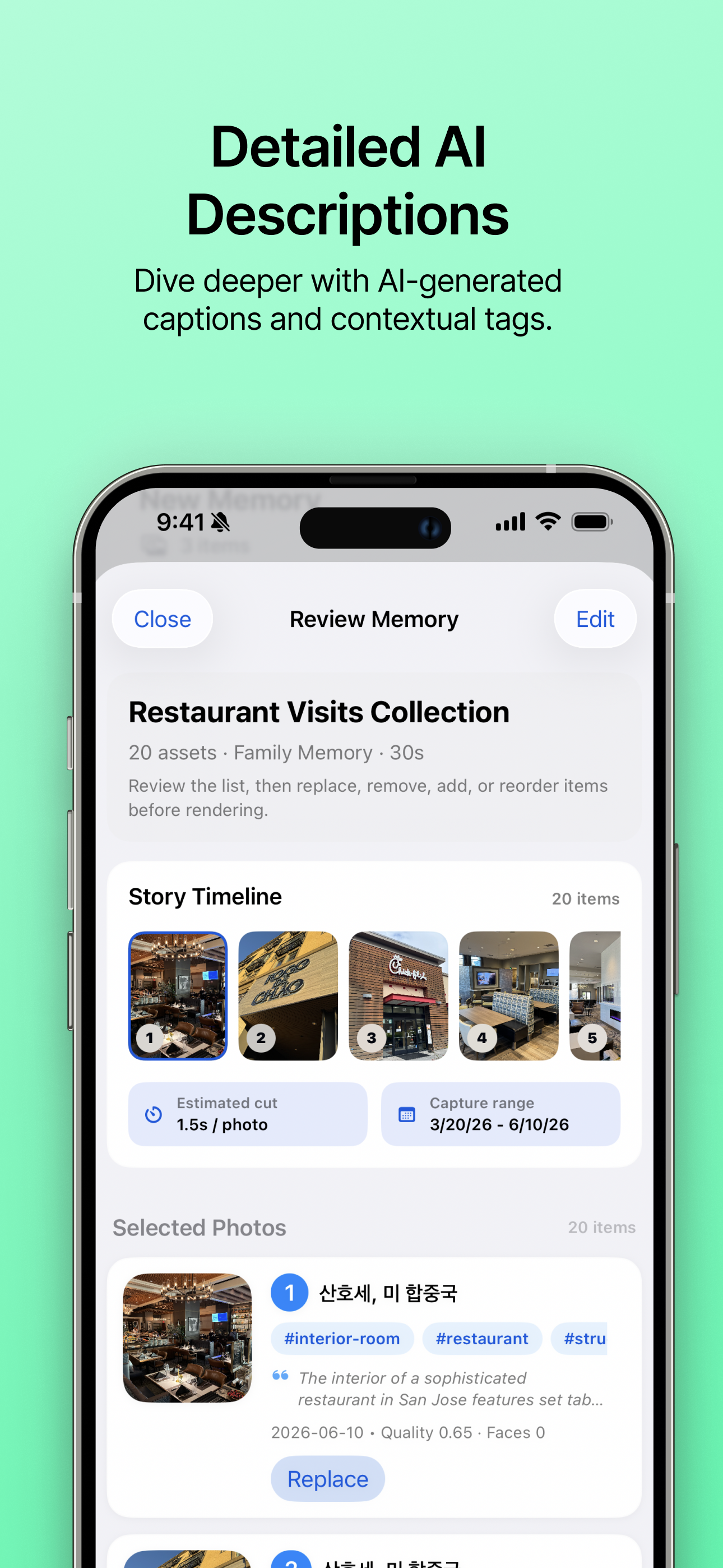
Profundiza con IA Analiza en profundidad con subtítulos y etiquetas contextuales generadas por IA. |
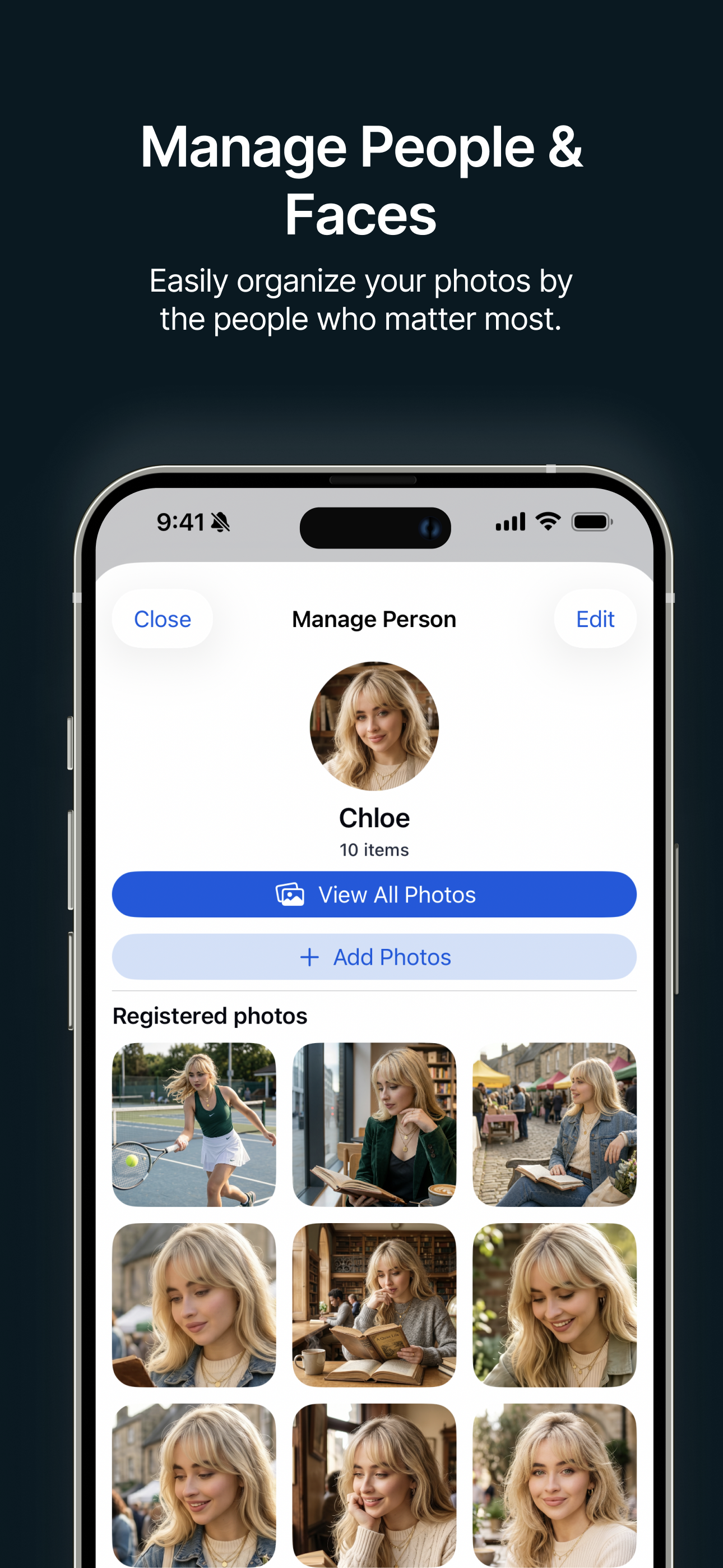
Organiza por personas Organiza fácilmente tus fotos según las personas que más te importan. |
 |
 |
 |
 |
 |
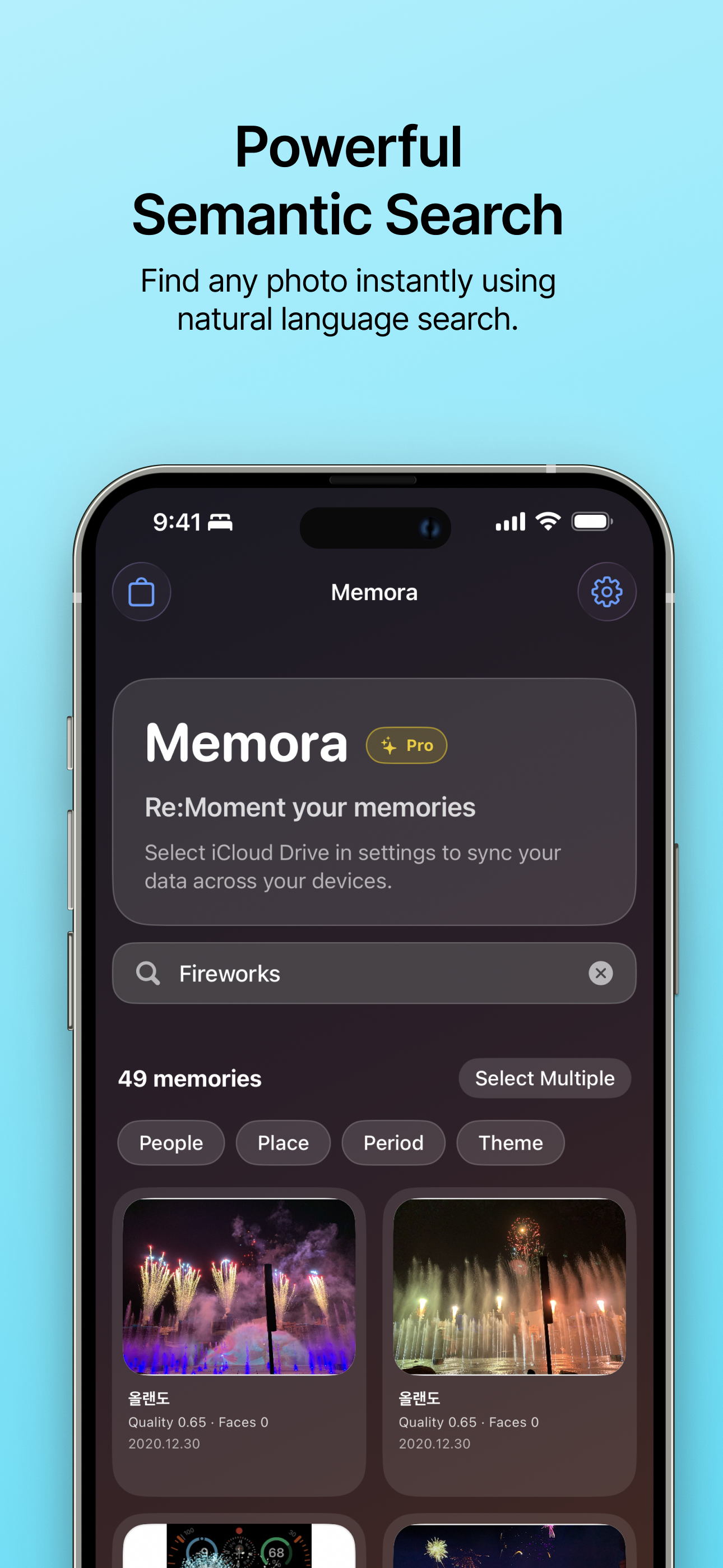
| Búsqueda instantánea de fotos Encuentra cualquier foto al instante usando búsqueda en lenguaje natural. |
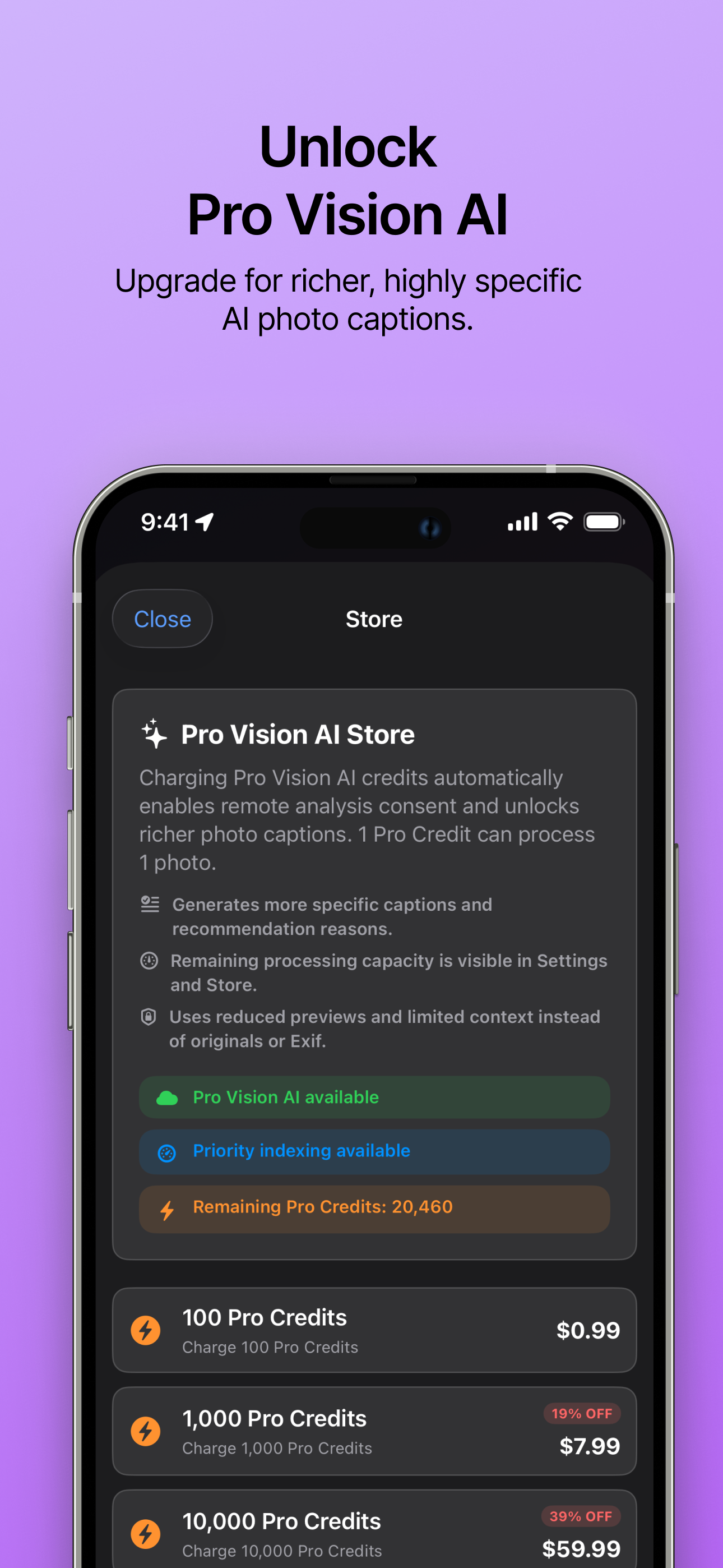
Pro Vision AI Actualiza para obtener subtítulos de IA más ricos y específicos. |
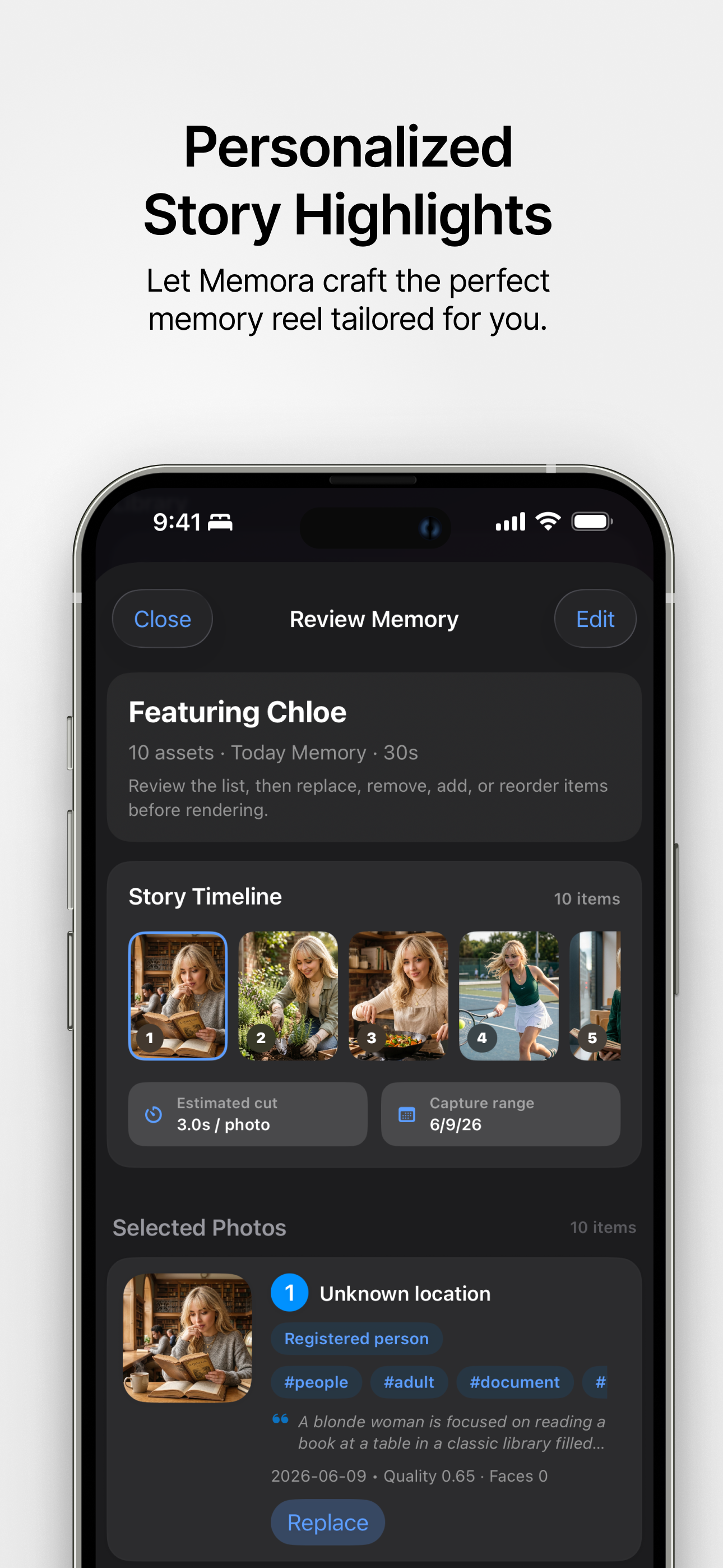
Destacados personalizados Deja que Memora cree el video de recuerdos perfecto a tu medida. |
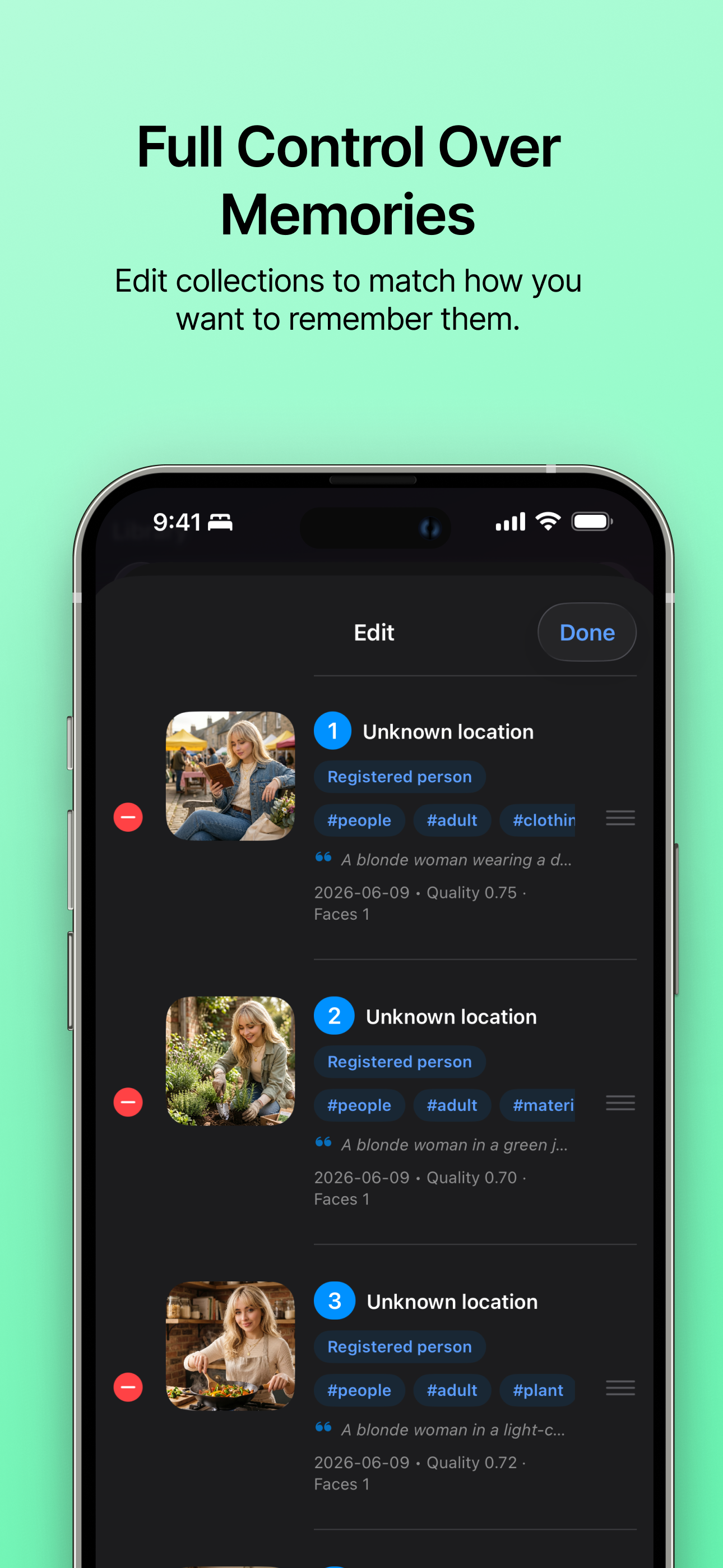
Edición personalizada de galería Edita fácilmente las colecciones para que coincidan con cómo quieres recordarlas. |
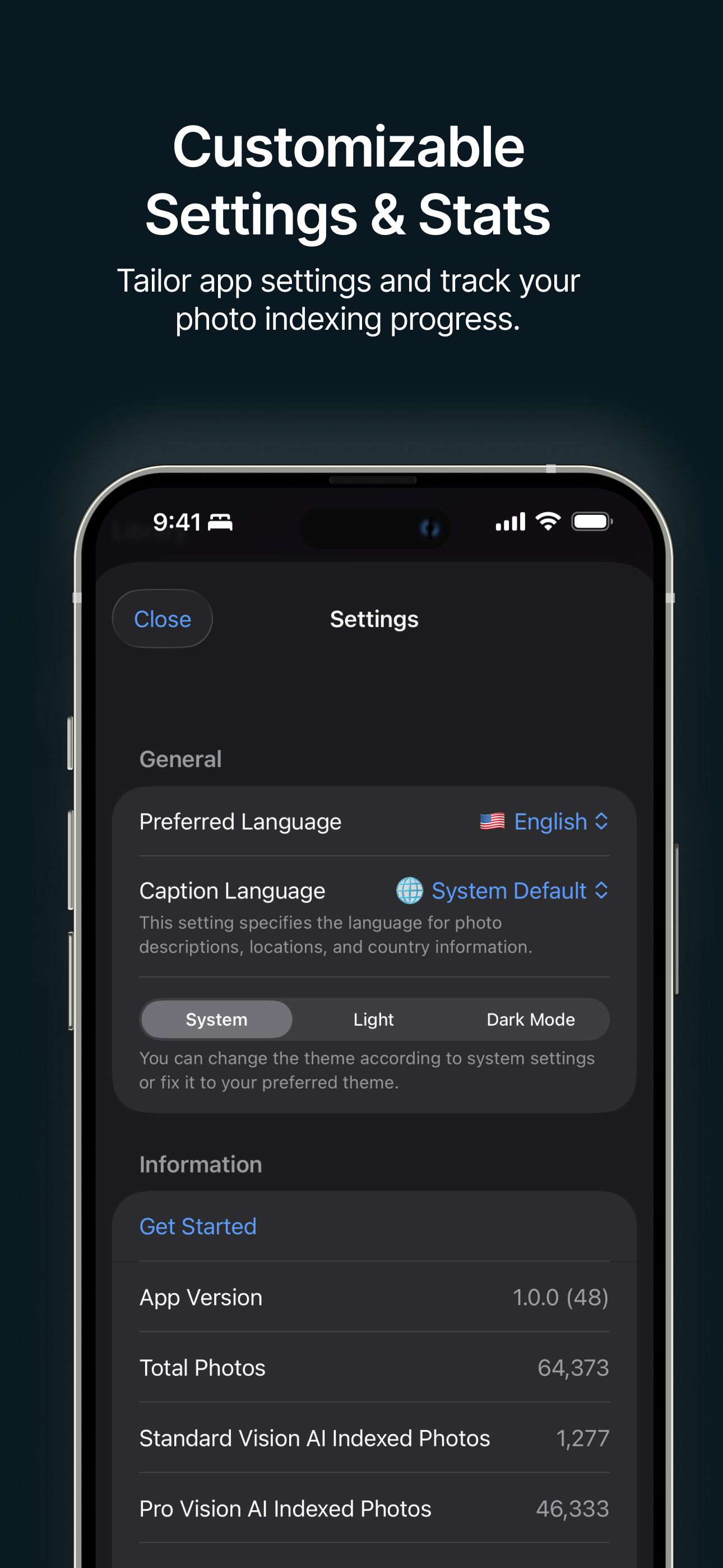
Configuración y estadísticas Personaliza la configuración de la app y haz un seguimiento del progreso. |
✨ Funciones principales
Recomendaciones inteligentes de historias
- Indexación de la biblioteca de fotos: Memora lee las fotos permitidas por el usuario con PhotoKit y extrae señales de fecha, ubicación, favoritos, tipo de medio, calidad, conteo de rostros, escena y subtítulos.
- Tarjetas de recomendación: La app crea candidatos de historias como momentos con la misma persona, fondos similares, comidas, recuerdos estacionales, ciudad/viaje, instantáneas temporales, momentos significativos y destacados de video.
- Búsqueda y mantenimiento: Las fotos indexadas se pueden buscar localmente. También hay acciones para completar traducciones, reparar coherencia, reiniciar comentarios de recomendación y ayudar a reanudar la indexación.
- Configuración de Prioridad de Escaneo: Ajusta la prioridad de escaneo de indexación directamente desde las preferencias de la aplicación.
- Modo de Escaneo Rápido: Una opción de escaneo basada en reglas para resultados más rápidos.
Historias de recuerdos revisables
- Revisión de historias: Antes de renderizar, los usuarios pueden revisar una historia sugerida, reemplazar o quitar fotos mediante vista previa a pantalla completa y búsqueda, agregar más candidatos, reordenar recursos y registrar personas representativas desde fotos con rostros claros.
- Controles de feedback: Los usuarios pueden archivar historias generadas, ocultar una recomendación específica, ocultar tipos similares de recomendación y deshacer comentarios recientes.
- Soporte de personas: Los perfiles de personas registrados pueden usarse para crear historias centradas en personas y mejorar recomendaciones futuras.
Vision y almacenamiento local-first
- Predeterminado en el dispositivo: La indexación estándar y los subtítulos de respaldo usan PhotoKit, Vision y análisis de metadatos locales. Las fotos no se envían al servidor salvo que el usuario active y use Pro Vision AI.
- Base de datos local: Memora guarda índices, historias, trabajos de renderizado, preferencias, puntos de control y perfiles de personas de forma estrictamente segura en el sandbox local de la app con SwiftData.
- Diagnósticos: MetricKit se usa para investigar bloqueos, cuelgues, arranque, CPU y problemas de escritura en disco. Estos diagnósticos no incluyen archivos de fotos del usuario.
- Interfaz de Descarga de IA Mejorada: Mejor seguimiento del progreso y actualizaciones dinámicas para los modelos de Vision AI en el dispositivo.
- Manifiestos Dinámicos de Modelos de Vision AI: Actualizaciones impulsadas por el backend para las configuraciones de modelos MLX en el dispositivo.
Pro Vision AI
- Función opcional de pago: Pro Vision AI usa un proxy del servidor para subtítulos VLM mejorados y control de cuota de indexación remota. Si no hay cuota o el servidor no está disponible, la app sigue funcionando con Vision AI local estándar.
- Control del servidor: El backend verifica el estado de derechos de StoreKit, emite tokens de acceso de corta duración, aplica cuotas, protege claves API del proveedor, gestiona idempotencia y registra señales contra abusos.
- Manejo de imágenes: Las cargas de imagen se reenvían solo para la operación de subtitulado solicitada. El servicio está diseñado para no almacenar bytes originales de imagen para uso del producto ni entrenamiento de IA. Pueden conservarse registros operativos como metadatos sanitizados de solicitud, texto de respuesta del proveedor, estado de solicitud, contadores de cuota, hashes de dispositivo e información de errores para derechos, cuotas, depuración, seguridad y prevención de abuso.
Renderizado y guardado de video
- Renderizador nativo: Las historias se renderizan con AVFoundation desde recursos de foto en caché, con objetivo predeterminado de 30fps y efectos de movimiento/transición como dissolve, slide, wipe y zoom.
- Exportación a Fotos: Antes de renderizar, Memora prepara copias locales de recursos solo en iCloud cuando es necesario. Los videos renderizados se guardan en Fotos con permiso add-only y fallback MOV compatible.
- Progreso y cancelación: La app muestra estados de descarga, renderizado, guardado, fallo, cancelación y recuperación.
❓ FAQ (Preguntas Frecuentes)
-
¿Por qué la indexación es tan lenta? Memora funciona en modo Estándar y Pro. El modo Estándar utiliza el modelo de IA directamente en su dispositivo, lo que puede llevar mucho tiempo debido a la naturaleza del procesamiento local. Para una indexación significativamente más rápida y subtítulos de mayor calidad, puede adquirir la suscripción a Pro Vision AI en la tienda.
-
¿Se guardan mis fotos en un servidor? No, sus fotos nunca se guardan en nuestros servidores. En el modo Estándar, todo ocurre localmente en su dispositivo. Incluso al usar Pro Vision AI, las imágenes solo se envían al servidor momentáneamente para su procesamiento, se descartan inmediatamente después y nunca se almacenan ni se utilizan para entrenar a la IA.
-
¿Tengo que comprar algo para usar la aplicación? No, las funciones principales de Memora son completamente gratuitas. Puede usar el modo Estándar para indexar sus fotos y crear historias sin pagar nada. Pro Vision AI es una función de pago opcional para los usuarios que desean un procesamiento más rápido y subtítulos de imágenes más detallados.
-
¿Estoy usando Pro, pero la indexación sigue siendo lenta? Esto podría ser un problema de conexión en segundo plano. Fuerce el cierre de la aplicación (deslice hacia arriba en el selector de aplicaciones) y vuelva a abrirla. Además, dado que el modo Pro requiere comunicación con nuestros servidores, asegúrese de tener una conexión a Internet estable.
-
¿Puedo hacer una copia de seguridad de mis datos? Sí. Puede exportar una copia de seguridad de sus índices, historias y preferencias a un archivo utilizando la función “Configuración > Copia de seguridad y restauración > Copia de seguridad de base de datos” en Memora para guardarla en el almacenamiento de su elección. (Nota: esto hace una copia de seguridad de los datos de la aplicación, no de sus archivos de fotos originales).
-
¿Puedo restaurar mis datos respaldados? Sí. Puede restaurar sus datos importando un archivo de copia de seguridad previamente exportado mediante la función “Configuración > Copia de seguridad y restauración > Restauración de base de datos” en Memora.
-
¿Por qué la pantalla se oscurece durante la indexación de fotos? La indexación solo continúa mientras la pantalla está encendida. Para ahorrar batería y evitar quemaduras en la pantalla, Memora reduce automáticamente el brillo de la pantalla al mínimo después de 5 minutos de indexación continua. Recomendamos encarecidamente conectar su dispositivo a la corriente durante largas sesiones de indexación.
-
¿La pantalla es demasiado brillante por la noche? Puede bajar manualmente el brillo de su dispositivo o usar el Modo oscuro. Si deja la aplicación indexando, Memora atenuará automáticamente la pantalla después de 5 minutos.
-
¿La pantalla se oscurece demasiado durante el día? Puede aumentar manualmente el brillo del dispositivo o desactivar el Modo oscuro. Memora atenúa intencionalmente la pantalla después de 5 minutos de indexación para ahorrar batería. Si necesita revisar la pantalla, simplemente tóquela o ajuste el brillo manualmente a través del Centro de control.
-
¿El dispositivo se calienta durante la indexación? El modo Estándar utiliza en gran medida el procesador de su dispositivo y el Neural Engine, lo que naturalmente hace que se caliente. El modo Pro descarga la computación pesada en nuestros servidores, reduciendo significativamente el calor del dispositivo y el consumo de batería. Si el calor es incómodo, considere pausar la indexación, enchufar su dispositivo o actualizar a Pro Vision AI para una experiencia más fresca y rápida.
📌 Notas importantes
- Memora requiere acceso de lectura a Fotos para indexar y recomendar historias. El acceso limitado está soportado, pero el acceso completo ofrece la experiencia prevista.
- Guardar videos renderizados requiere permiso de agregar a Fotos.
- Pro Vision AI envía temporalmente las imágenes seleccionadas al backend y al proveedor VLM configurado para generar datos de subtítulos. Sin embargo, tenga la seguridad de que todas las fotos se eliminan inmediatamente después de que se generan los subtítulos sin ser almacenadas.
- Los subtítulos y recomendaciones generados por IA pueden ser inexactos. Revisa el contenido antes de renderizarlo o compartirlo.
- Los nombres de producto, cuotas, precios y disponibilidad de plataformas pueden cambiar antes o después del lanzamiento en App Store.
🛠 Stack tecnológico
Cliente
- Swift 6, SwiftUI, SwiftData
- PhotoKit, Vision, AVFoundation, MetricKit
- Paquetes relacionados con MLX Swift LM / MLX VLM, Swift HuggingFace, Swift Transformers
Servidor
- FastAPI, Uvicorn, Starlette
- PostgreSQL, SQLAlchemy, Alembic, Psycopg 3
- Pydantic, Pydantic Settings, HTTPX
- PyJWT y cryptography para rutas de verificación de StoreKit y tokens
📜 Políticas y licencias
📄 Licencia
Copyright © 2026 MFLab-AI (https://lab.missflash.com/). All rights reserved.
El código fuente, recursos, marca, documentación y materiales relacionados de Memora son propietarios salvo que exista una licencia escrita separada. Los componentes open-source de terceros se rigen por sus propias licencias.